스파르타 통계학 기초 강의 정리 1
● 기술통계 : 데이터를 특정 대표값(평균, 중앙값, 분산, 표준편차 등)으로 요약하고 설명하는 통계 방법
- 분산 : 각 데이터 값에서 평균을 뺀 값(평균으로부터의 거리)을 제곱 후, 이 값들의 평균을 구한 값
- 표준편차 : 분산의 제곱근(루트)
● 추론통계 : 표본 데이터를 통해 모집단의 특성을 추정하고 가설을 검정하는 통계 방법
- 신뢰구간 : 모집단의 평균이 특정 범위 내에 있을 것이라는 확률
- 가설검정 : 모집단에 대한 가설을 검증하기 위해 사용됨
▶ 귀무가설(H0) : 검증하고자 하는 가설이 틀렸음을 나타내는 기본 가설 > 변화 없음, 효과 없음
▶ 대립가설(H1) : 검증하고자 하는 가설이 맞음을 나타내는 가설 > 변화 있음, 효과 있음
>>> p-value를 통해 귀무가설을 기각할지 여부를 결정(ex 0.05이하일 경우 귀무가설을 기각)
# 다양한 분석 방법
# 데이터 분석에서 자주 사용되는 라이브러리
import pandas as pd
# 다양한 계산을 빠르게 수행하게 돕는 라이브러리
import numpy as np
# 시각화 라이브러리
import matplotlib.pyplot as plt
# 시각화 라이브러리2
import seaborn as sns
■ 위치 추정(평균, 중앙값)
data = [85, 90, 78, 92, 88, 76, 95, 89, 84, 91]
mean = np.mean(data)
median = np.median(data)
print(f"평균: {mean}, 중앙값: {median}")평균: 86.8, 중앙값: 88.5
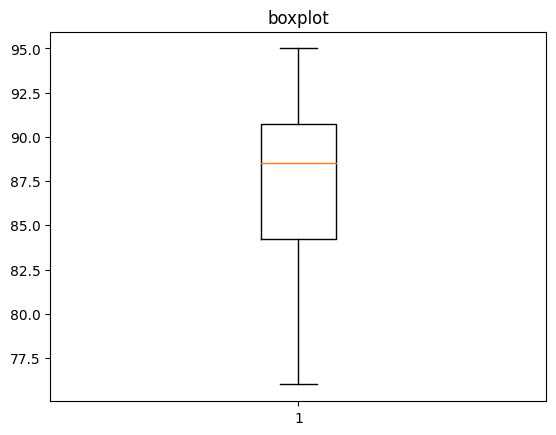
■ 변이 추정(분산, 표준편차, 범위(range))
variance = np.var(data)
std_dev = np.std(data)
data_range = np.max(data) - np.min(data)
print(f"분산: {variance}, 표준편차: {std_dev}, 범위: {data_range}")분산: 33.36, 표준편차: 5.775811631277461, 범위: 19
■ 데이터 분포 탐색(데이터를 한 눈에 보기 - 히스토그램, 상자 그림(Box plot))
plt.hist(data, bins=5)
plt.title('histogram')
plt.show()
plt.boxplot(data)
plt.title('boxplot')
plt.show()
■ 이진 데이터와 범주형 데이터 탐색 : 데이터들이 서로 얼마나 다른지 - 최빈값을 주로 사용(파이그림, 막대 그래프)
satisfaction = ['satisfaction', 'satisfaction', 'dissatisfaction',
'satisfaction', 'dissatisfaction', 'satisfaction', 'satisfaction',
'dissatisfaction', 'satisfaction', 'dissatisfaction']
satisfaction_counts = pd.Series(satisfaction).value_counts()
satisfaction_counts.plot(kind='bar')
plt.title('satisfaction distribution')
plt.show()
■ 상관관계 : 데이터들끼리 서로 관련이 있는지
study_hours = [10, 9, 8, 7, 6, 5, 4, 3, 2, 1]
exam_scores = [95, 90, 85, 80, 75, 70, 65, 60, 55, 50]
correlation = np.corrcoef(study_hours, exam_scores)[0, 1]
print(f"공부 시간과 시험 점수 간의 상관계수: {correlation}")
plt.scatter(study_hours, exam_scores)
plt.show()
공부 시간과 시험 점수 간의 상관계수: 1.0

■ 다변량 분석 : 여러 변수 간의 관계를 분석
data = {'TV': [230.1, 44.5, 17.2, 151.5, 180.8],
'Radio': [37.8, 39.3, 45.9, 41.3, 10.8],
'Newspaper': [69.2, 45.1, 69.3, 58.5, 58.4],
'Sales': [22.1, 10.4, 9.3, 18.5, 12.9]}
df = pd.DataFrame(data)
sns.pairplot(df)
plt.show()
df.corr()
# heatmap까지 그린다면
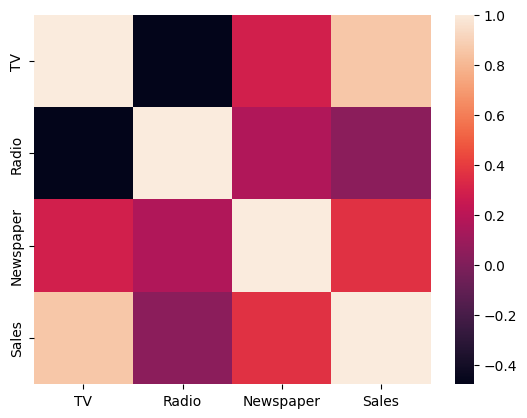
sns.heatmap(df.corr())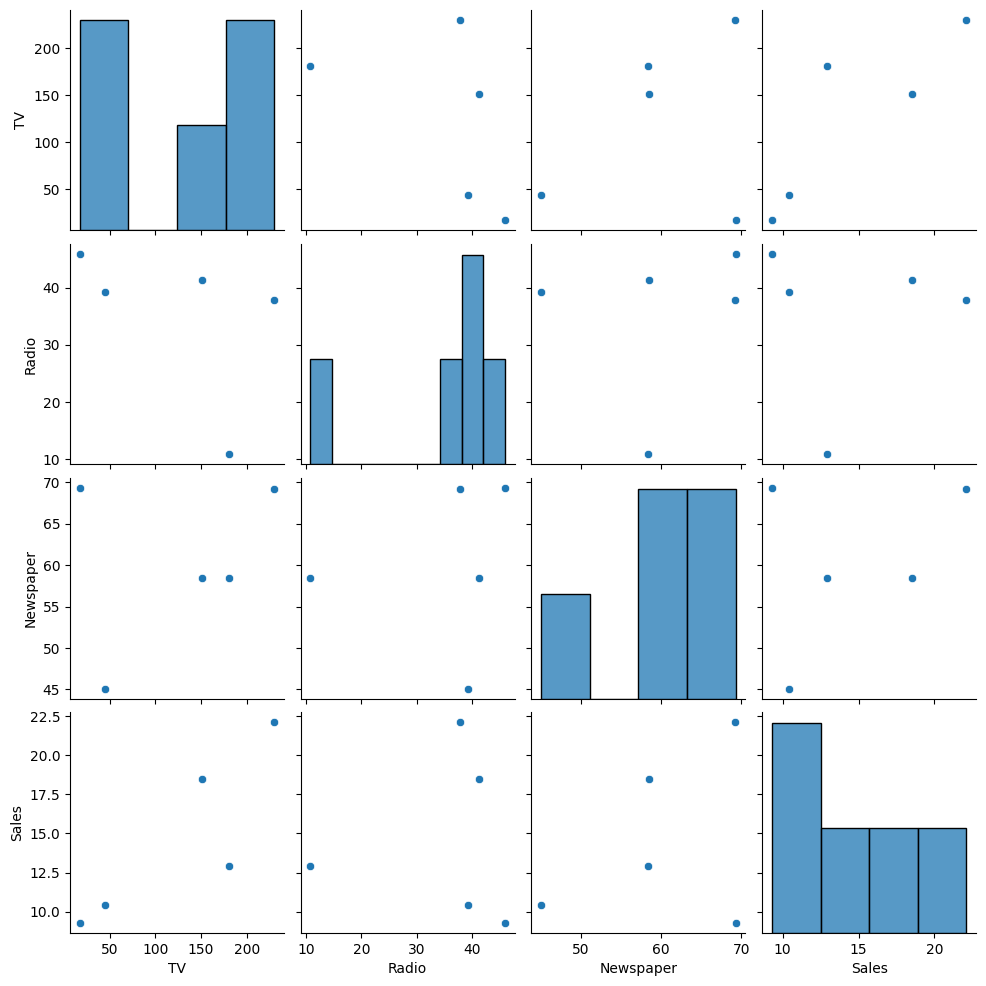
TV Radio Newspaper Sales
TV 1.000000 -0.478276 0.285756 0.857632
Radio -0.478276 1.000000 0.166737 0.035758
Newspaper 0.285756 0.166737 1.000000 0.362066
Sales 0.857632 0.035758 0.362066 1.000000