# 비지도 학습 : 답(Y)을 알려주지 않고 데이터 간 유사성을 이용해서 답(Y)을 지정하는 방법
K-Means Clustering 이론
① K개 군집 수 설정
② 임의의 중심을 선정
③ 해당 중심점과 거리가 가까운 데이터를 그룹화
④ 데이터의 그룹의 무게 중심으로 중심점을 이동
⑤ 중심점을 이동했기 때문에 다시 거리가 가까운 데이터를 그룹화 (3~5번 반복)
▶ 장점
- 일반적이고 적용하기 쉬움
▶ 단점.
- 거리 기반으로 가까움을 측정하기 때문에 차원이 많을 수록 정확도가 떨어짐
- 반복 횟수가 많을 수록 시간이 느려짐
- 몇 개의 군집(K)을 선정할지 주관적임
- 평균을 이용하기 때문에(중심점) 이상치에 취약함
▷ Python 라이브러리
sklearn.cluster.KMeans
- 함수 입력 값
n_cluster : 군집화 갯수
max_iter : 최대 반복 횟수
- 메소드
labels_ : 각 데이터 포인트가 속한 군집 중심점 레이블
cluster_centers : 각 군집 중심점의 좌표
군집평가 지표
● 실루엣 계수
- 실루엣 분석(silhouette analysis) : 군집 간의 거리가 얼마나 효율적으로 분리되어 있는지 측정
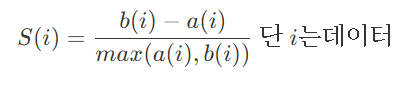
# (1에서 -1의 값) : 1에 가까울수록 데이터 포인트가 자신이 속한 클러스터 내에 잘 속해 있으며, 다른 클러스터와는 명확하게 구분된다는 뜻. 즉, 클러스터 간의 경계가 뚜렷하고, 데이터 포인트들이 적절하게 그룹화되었다는 것
# 데이터의 차이(거리)를 데이터 중에서 큰 값으로 나눈 값
▷ Python 라이브러리
# 전체 데이터의 실루엣 계수 평균 값 반환
sklearn.metrics.sihouette_score
- 함수 입력 값
X: 데이터 세트
labels: 레이블
metrics: 측정 기준 >> 기본은 euclidean
# iris 데이터를 통한 실습
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# iris 데이터에서 y값(species)가 없다고 가정하고 진행
iris_df = sns.load_dataset('iris')
iris_df.info() # 결측치 확인
sns.scatterplot(data = iris_df, x = 'sepal_length', y = 'sepal_width') # 군집화 전 시각화
# y를 모른다고 가정하고 데이터 프레임을 만든 후 군집화를 해보기
iris_df2 = iris_df[['sepal_length', 'sepal_width', 'petal_length', 'petal_width']]
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters = 3, init = 'k-means++', max_iter = 300, random_state= 42)
kmeans.fit(iris_df2)
# n_clusters = 3 클러스터의 개수를 지정하는 매개변수, 데이터를 몇 개의 그룹으로 나눌것인지 설정(기본값 8)
# init='k-means++ 초기 중심점을 더 스마트하게 선택하여 수렴 속도와 정확성을 높인다. random 이면 무작위로 선택
# max_iter=300 반복 횟수(기본값 300)
kmeans.labels_ # 정보 확인
iris_df2['target'] = iris_df['species'] # 군집화하고 싶은 target 지정(가정은 원래 모른다고 하는 것)
iris_df2['cluster'] = kmeans.labels_ # 군집화된 정보
# ~ 별로 보고싶다는 태깅을 할때 hue 사용
sns.scatterplot(data = iris_df, x = 'sepal_length', y = 'sepal_width', hue = 'species')
# 군집화한 그래프 시각화
plt.subplot(1,2,2)
sns.scatterplot(data = iris_df2, x = 'sepal_length', y = 'sepal_width', hue = 'cluster', palette = 'viridis')
plt.title('Clustering')
plt.show()
# y 값을 알때의 원래 그래프의 모습
plt.figure(figsize = (12,6))
plt.subplot(1,2,1)
sns.scatterplot(data = iris_df2, x = 'sepal_length', y = 'sepal_width', hue = 'target')
plt.title('Original')'머신러닝' 카테고리의 다른 글
| 머신러닝 심화과정(딥러닝) (1) | 2024.08.21 |
|---|---|
| 머신러닝 심화과정(회귀, 분류 모델링 심화) - 고객 세그멘테이션 실습(군집화) (0) | 2024.08.20 |
| 머신러닝 심화과정(회귀, 분류 모델링 심화) - 최근접 이웃(KNN), 부스팅 (0) | 2024.08.19 |
| 머신러닝 심화과정(회귀, 분류 모델링 심화) - 의사결정나무 / 랜덤 포레스트 (1) | 2024.08.19 |
| 머신러닝 심화과정(데이터분석 프로세스) - 실습하기, 교차검증, GridSearch (0) | 2024.08.18 |
